


DeepSeek: Beyond the Hype—A Game Changer
DeepSeek: Beyond the Hype—Redefining the Future of AI


What do Silicon Valley and Hangzhou have in common? Until yesterday—nothing. But when DeepSeek unveiled its new AI model, built for just $5.5 million, tech giants scrambled for emergency meetings.
While companies like OpenAI and Anthropic pour billions into AI development, a small Chinese team proved that cutting-edge models don’t require massive budgets. DeepSeek introduced two models—DeepSeek V3 and DeepSeek R1—each making waves in the industry.
DeepSeek V3: A Small-Scale Revolution
OpenAI’s Sam Altman once claimed training GPT-4 required billions. DeepSeek just shattered that notion. With only $5.5 million, their latest model delivers impressive results, raising a crucial question—do AI advancements need astronomical investments?
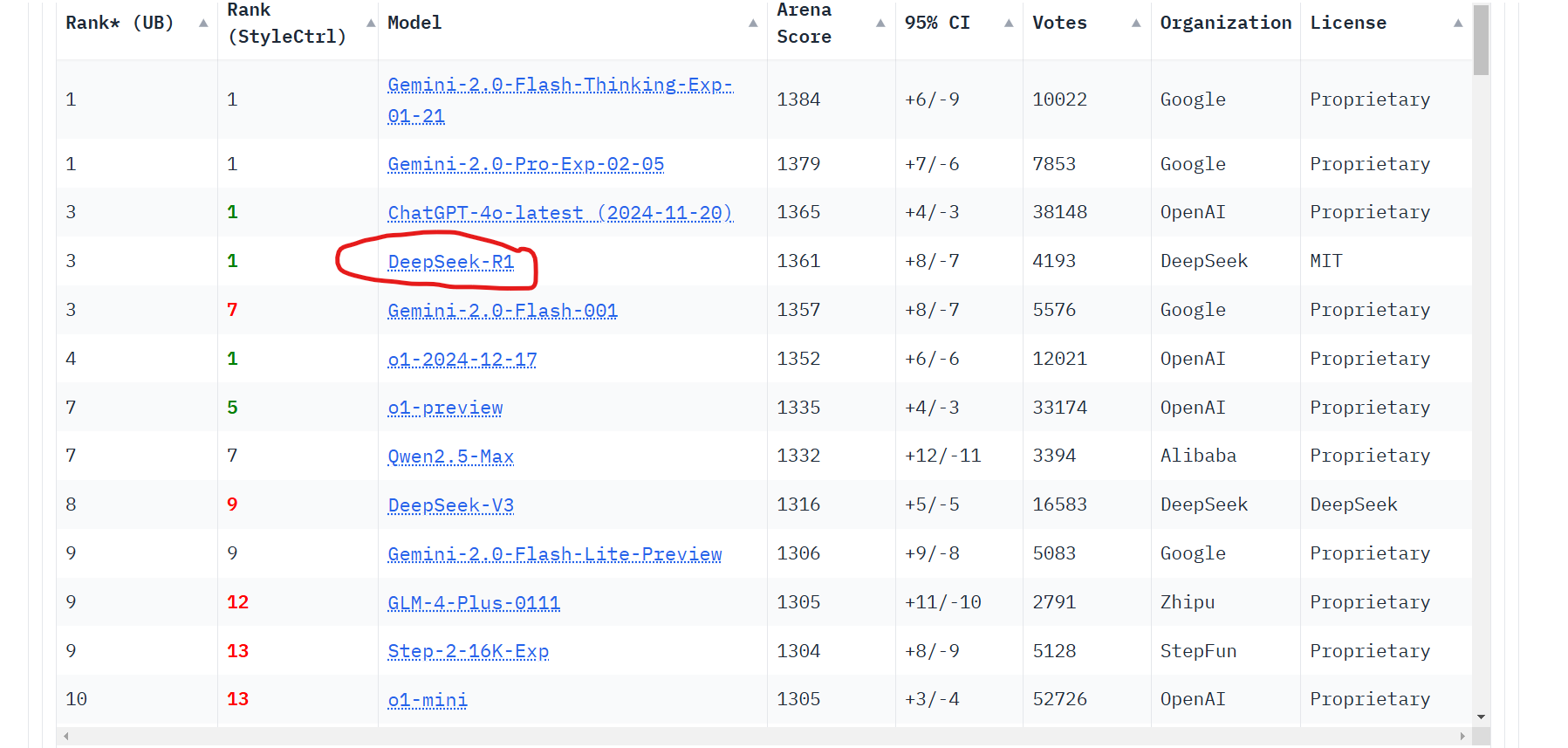
Market Reaction
As a pioneer in the field, OpenAI naturally required more resources. However, DeepSeek's success has still made investors question the true cost of building competitive AI models.

Market Shock
The launch of DeepSeek V3 sent shockwaves through the stock market, prompting investors to ask tough questions:
Why did OpenAI spend billions when similar results were achieved for millions?
Are current AI company valuations justified?
Are Western tech giants overvalued?
Interestingly, Nvidia— a key supplier and technical partner for many AI firms— took the biggest hit.

Why So Affordable?
DeepSeek significantly cut training costs using several key strategies:
Optimized architecture – The Mixture of Experts (MoE) model reduces computational demands.
Synthetic training data – This approach provided vast amounts of training data at a fraction of the cost.
A major advantage was DeepSeek’s reliance on open-source models, specifically open weights. By leveraging prior advancements from other open AI projects—like Meta’s LLaMa—DeepSeek accelerated development without massive investment.
Smarter, Not Bigger
DeepSeek’s competitive edge comes from its Mixture of Experts (MoE) architecture, already proven in models like Mixtral by Mistral AI, enabling smarter, more efficient AI without excessive costs.
The Secret Behind DeepSeek’s Success
A key factor in DeepSeek’s breakthrough is its use of Mixture of Experts (MoE). This approach makes the model more efficient, focusing on smarter processing rather than just increasing size and cost. Inspired by Mixtral from Mistral AI, DeepSeek demonstrates how neural networks can achieve high performance without massive expenses.
In fact, DeepSeek has been refining this approach for over a year. In a January 11, 2024 publication, they introduced their own method designed to further reduce computational demands.

The True Cost of Innovation
The claim that DeepSeek trained its model for just $5.5 million raises some skepticism. The company is backed by High-Flyer, a Chinese hedge fund with extensive in-house GPU resources used for market predictions. This significantly reduces infrastructure costs.
Moreover, training large language models involves numerous experiments. The reported figure may only reflect successful runs, while failed attempts remain undisclosed.
Data Privacy Concerns
Some have questioned DeepSeek’s data privacy policies. While the models are marketed as open and free, there’s no guarantee that user data isn’t being collected.
Given the company’s Chinese origins, this raises concerns among Western users and businesses. However, OpenAI and other major AI firms also gather data for model refinement. The key difference lies in jurisdiction, not practice.
That said, unlike many competitors, DeepSeek’s models can be run independently, reducing reliance on third-party servers and mitigating privacy risks.
DeepSeek R1: Transparent AI Reasoning
One standout feature of DeepSeek R1, positioned as an alternative to OpenAI’s o1, is its transparent decision-making. Unlike most models, which function as a black box, DeepSeek R1 reveals its reasoning step by step, making it particularly valuable for researchers and developers.
This approach unlocks new creative and optimization possibilities, comparable in scale to the impact that LLaMa 3's open model once had on the AI community.
Accessibility and Openness
DeepSeek is making AI more accessible, much like LLaMa and Mistral did before. By open-sourcing model weights, it allows:
Fine-tuning for specialized tasks
Building local AI solutions without massive training costs
However, DeepSeek's openness has limitations. While the company shares model weights, training data and optimization algorithms remain private—a strategy similar to Meta’s approach with LLaMa. This attracts developers while keeping core technology proprietary.
AI’s Future and Market Impact
Experts believe ChatGPT will remain dominant, but models like DeepSeek could drive down AI service costs.
Currently, ChatGPT’s premium plan costs $200/month. More affordable alternatives with similar capabilities could accelerate AI adoption on a broader scale.

Conclusion: The Changing Landscape of AI
DeepSeek has certainly shaken up the AI industry, challenging the conventional wisdom that only massive investments can lead to groundbreaking results. With its innovative approach, low-cost model training, and transparency in decision-making, it has proven that it's possible to create powerful AI systems without breaking the bank.
The DeepSeek V3 and R1 models have set a new standard for what is achievable with smart resource management and open-source collaboration. As more providers begin to offer DeepSeek models through platforms like OpenRouter, AI technology is becoming increasingly accessible to developers and businesses alike, offering opportunities to customize and deploy solutions with greater efficiency and lower costs.
As the AI landscape continues to evolve, DeepSeek’s success could inspire a shift towards more cost-effective and transparent models, challenging the dominance of tech giants like OpenAI. While ChatGPT may continue to lead in the mass market, the growing availability of competitive models could push the AI industry towards more affordable, scalable, and innovative solutions—creating exciting new possibilities for the future of AI.